Breast Cancer Classification
Breast cancer is a prevalent health concern affecting women globally. Early detection and accurate classification of breast tumors are critical for timely intervention and improved patient outcomes. Medical imaging, such as mammography, provides valuable data for the diagnosis of breast cancer. Developing a robust classification model can assist healthcare professionals in distinguishing between malignant and benign tumors with high accuracy using the description of the tissues. The goal of this project is to design and implement a machine learning model using RapidMiner tool for the classification of breast tumors as either malignant or benign based on relevant features extracted from diagnostic data set of the patient data.
Commonly, texture and morphological features of breast ultrasound images are used to analyse the benign and malignant of tumors. Another straightforward approach is to train classifiers based on texture and morphological features by a computer for classifying benign and malignant tumors automatically to overcome the subjectivity of manual ultrasound image analysis

Dataset Description
This is an analysis of the Breast Cancer Wisconsin (Diagnostic) Data Set, obtained from
Kaggle. This data set was created by Dr.William H. Wolberg, physician at the University Of
Wisconsin Hospital at Madison, Wisconsin,USA. To create the dataset Dr. Wolberg used fluid
samples, taken from patients with solid breast masses and an easy-to-use graphical computer
program called Xcyt, which is capable of perform the analysis of cytological features based on
a digital scan. The program uses a curve-fitting algorithm, to compute ten features from each
one of the cells in the sample, than it calculates the mean value, extreme value and standard
error of each feature for the image, returning a 30 real-valuated vector.
This dataset which contains 569 examples of malignant and benign tumor cells. The attribute
values used for supporting the classification are
ID
Diagnosis
radius
texture
perimeter
area
measured
smoothness
compactness
concavity
symmetry and many more.
Software:
Rapidminer Studio
Design Steps and Workflow
Following steps are involved in this project
- Data Loading
- Feature Selection-using Set Role
- Model Building
- Model Training
- Model Evaluation
- Visualization and Interpretation
Model description
Approach
To implement a Breast cancer model we first look for the best algorithm which can fetch good results. Here we use classification algorithms like Logistic regression , Random forest and Neural network to see which amongst these can give good accuracy. After selecting the algorithm which gives us the best results we proceed further with validation and mining the performance of the model to predict whether the breast cancer is benign or malignant. The model results in a confusion matrix from which we can predict the cancer type
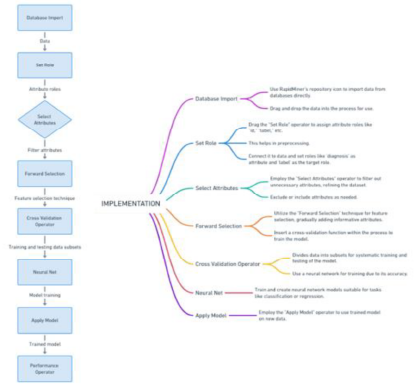
Steps for implementation
1.Database Import
RapidMiner allows us to connect to databases to import data directly. Use the repository icon to import data , after importing the data from system to RapidMiner we drag the data and drop in the process
2.Set role
In RapidMiner, the "Set Role" operator is used to assign roles to attributes in your dataset. Roles define the type of information an attribute holds, such as "id," "label," "regular," "weight," etc. Assigning roles is an important step in the data pre-processing phase, as it helps RapidMiner understand the nature of each attribute and facilitates the proper execution of various operators and processes. We drag the set role operator from the operator section , after dropping it we connect it to data. Set diagnosis to be our attribute name and label to be the target role. Select attribute In RapidMiner, the "Select Attributes" operator is used to choose a subset of attributes (columns) from a dataset. This operator allows you to filter out unnecessary or irrelevant attributes, reducing the dimensionality of your data and focusing on the most relevant features for analysis or modelling. Here we exclude or include the attribute, the attribute we’ve excluded is the id from the dataset
3.Forward selection
forward selection is a feature selection technique used in the context of building predictive models. Feature selection is the process of choosing a subset of relevant features from the original set of attributes to improve the model's performance and reduce complexity. Forward selection specifically involves gradually building up the set of features by iteratively adding the most informative attributes one at a time. We insert a cross validation function inside the forward selection. We make all connections and proceed with training our model
4.Cross validation operator
In RapidMiner, the Cross Validation operator is used for model evaluation, especially in the context of predictive modeling or machine learning. Cross-validation is a technique that helps assess how well a model is likely to perform on an independent dataset. It involves dividing the dataset into multiple subsets (folds) and systematically using each subset for both training and testing the model. Cross validation operator conducts training and testing operations , for training our model we train it using neural network as it gives more accuracy
5.Neural Net
Neural Net operator is used to create and train neural network models. Neural networks are a class of machine learning models inspired by the structure and function of the human brain. They are particularly well-suited for tasks such as pattern recognition, classification, regression, and other complex tasks
6.Apply Model
Apply Model operator is used to apply a trained predictive model to new, unseen data. Once you have developed and trained a model using a training dataset, you can use the "Apply Model" operator to make predictions on different or future data. In cross validation we make connections from the neural net in the training side to apply models in the testing part. We make our last connection by adding a performance operator on the testing side of cross validation and connecting it to the result
7.Performance operator
Performance operator is used to evaluate the performance of a predictive model. After building a model using algorithms such as decision trees, support vector machines, or other machine learning techniques, it's crucial to assess how well the model generalizes to new, unseen data. The "Performance" operator provides various metrics and visualizations to help you understand the model's effectiveness
Output
Performance operator is used to evaluate the performance of a predictive model. After building a model using algorithms such as decision trees, support vector machines, or other machine learning techniques, it's crucial to assess how well the model generalizes to new, unseen data. The "Performance" operator provides various metrics and visualizations to help you understand the model's effectiveness
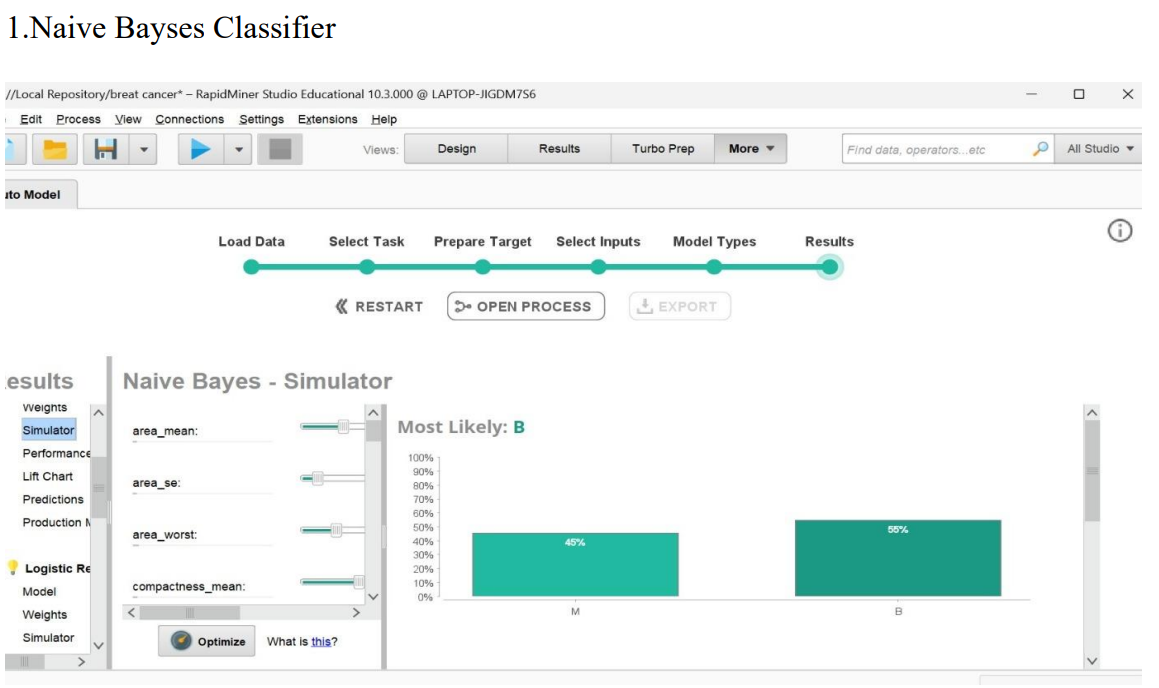
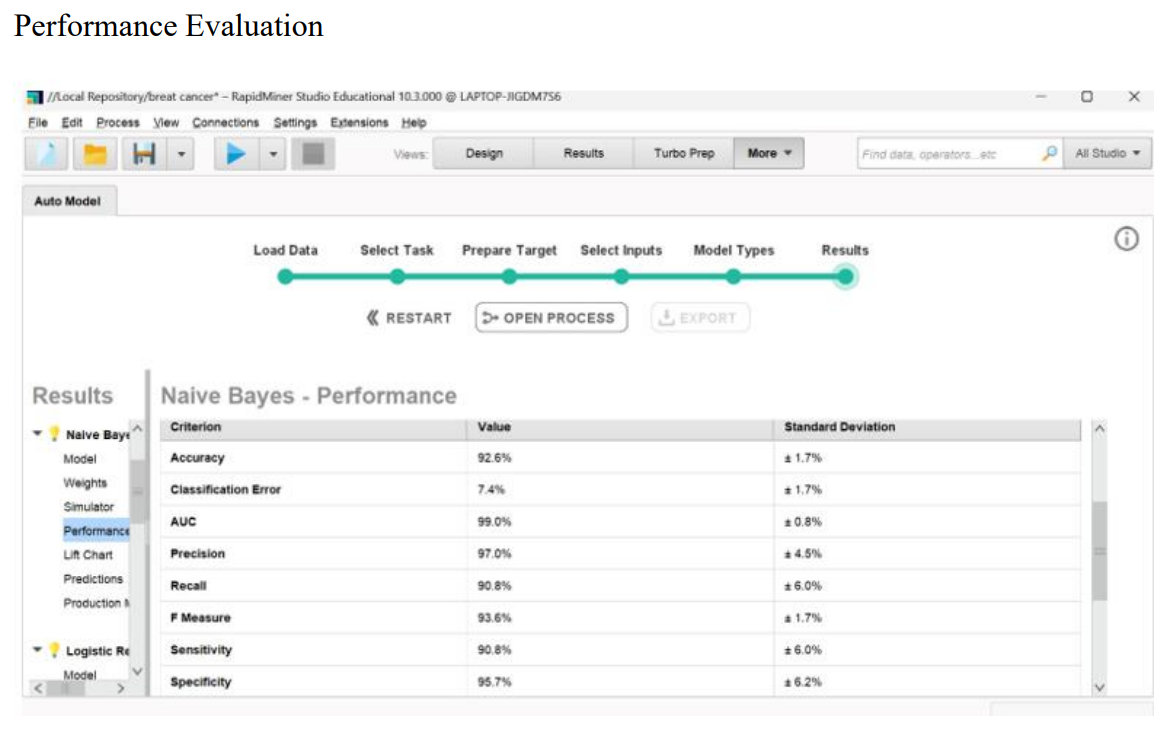
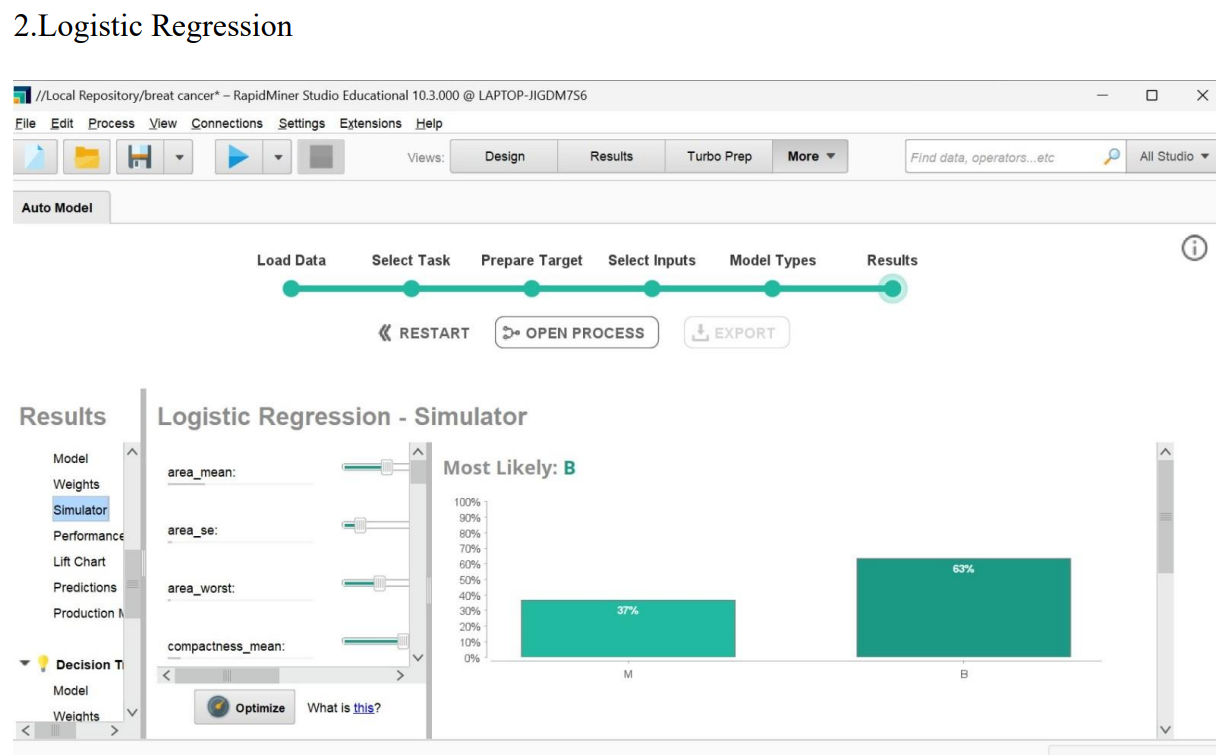
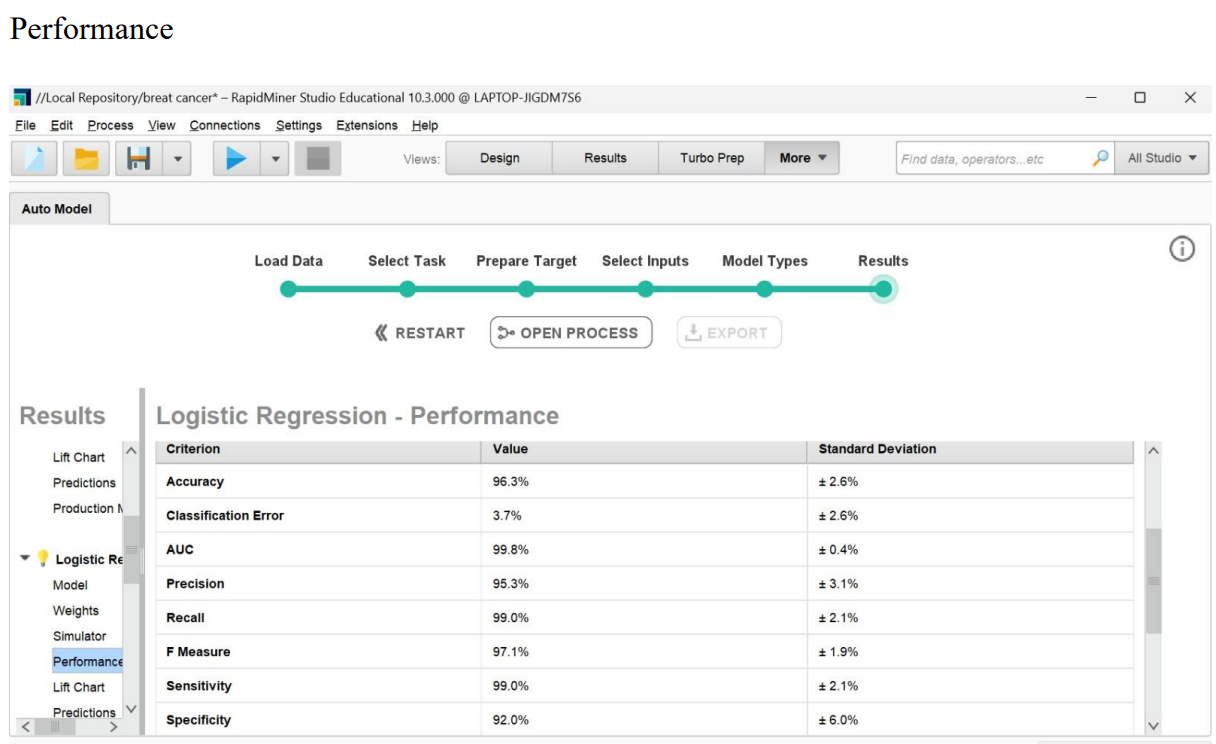
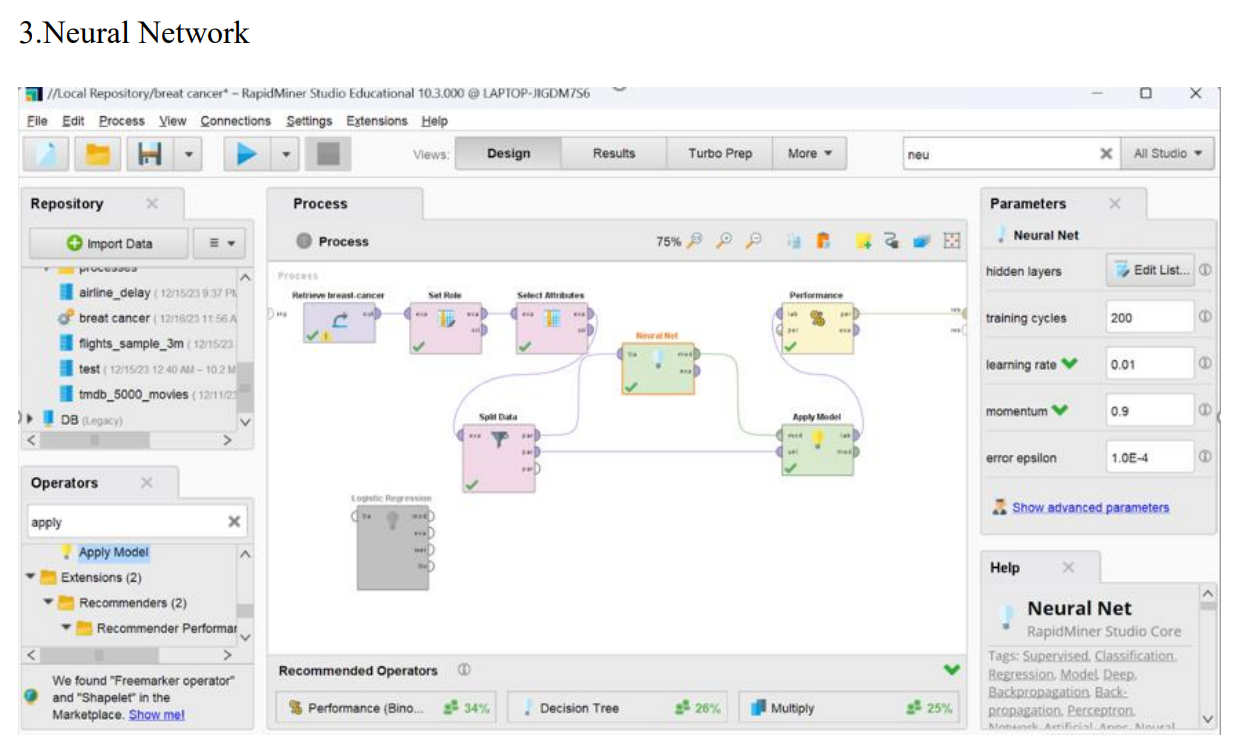
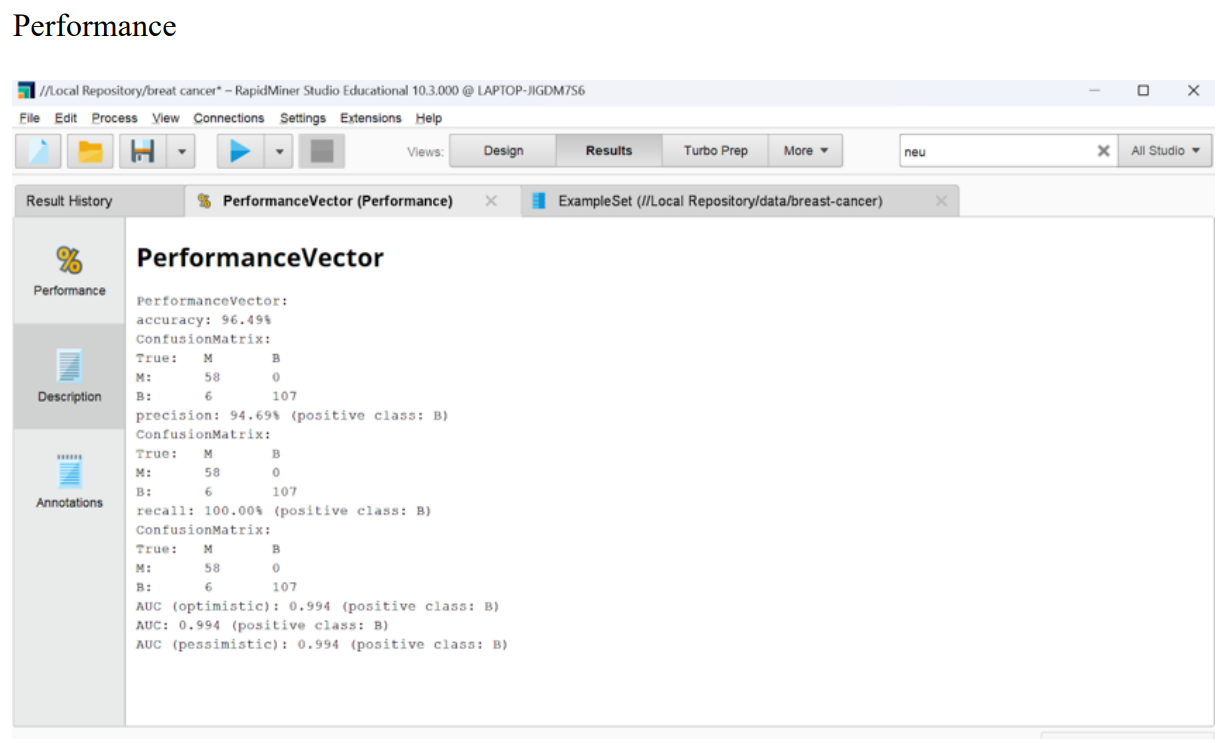
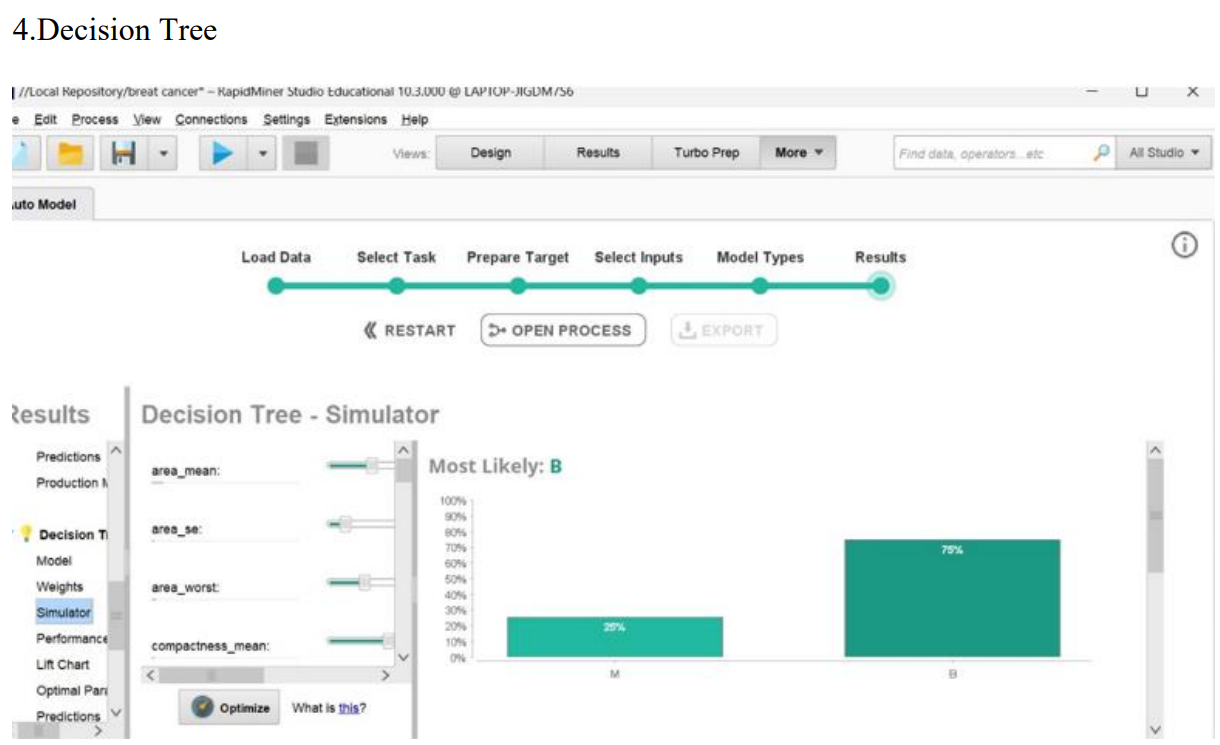
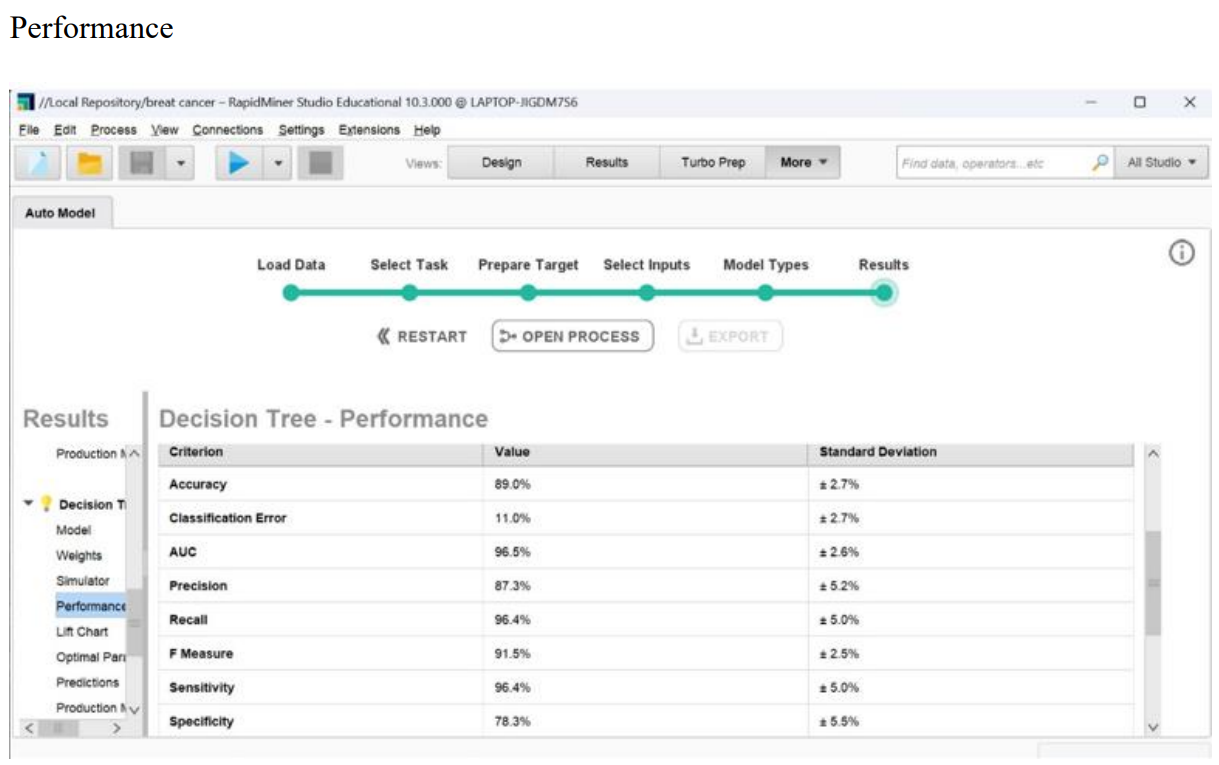
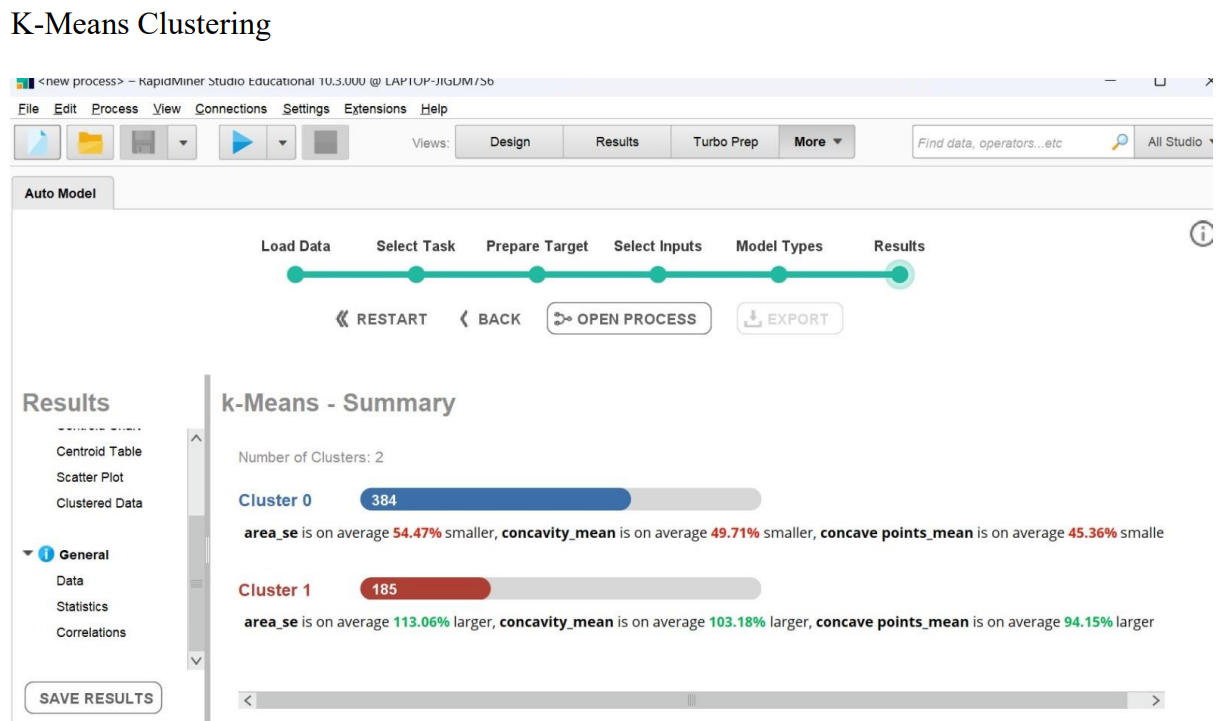
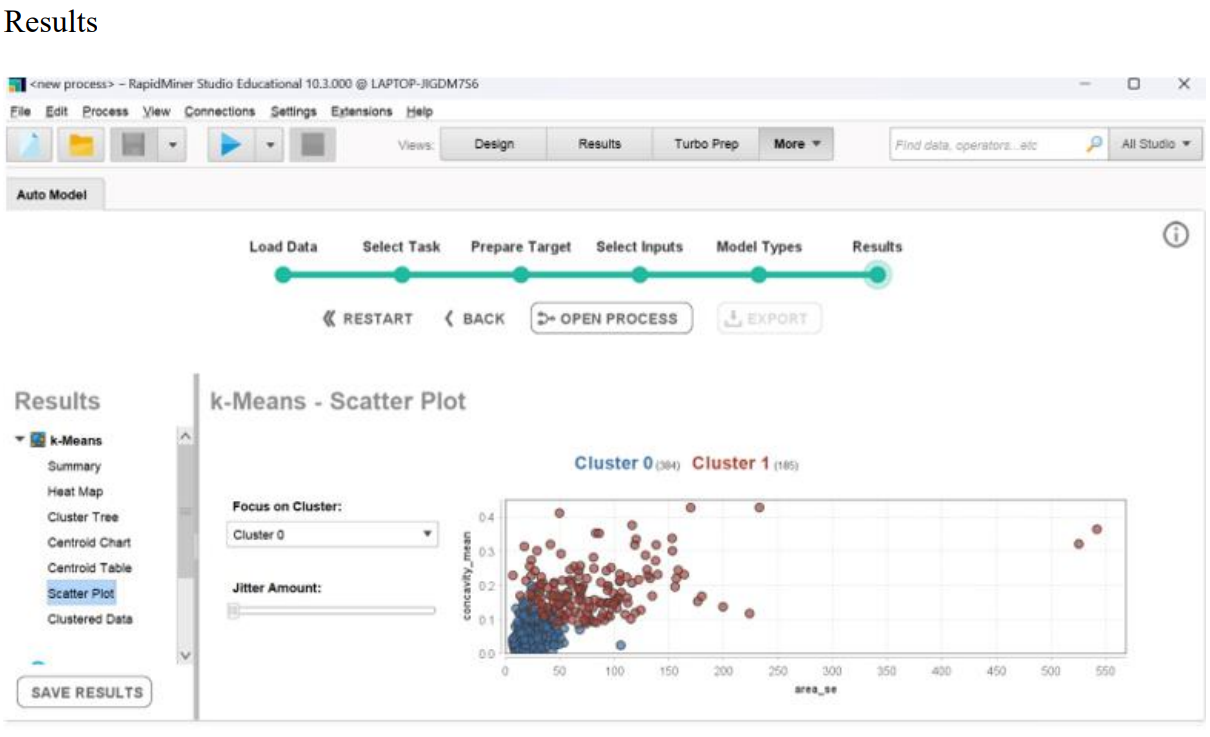
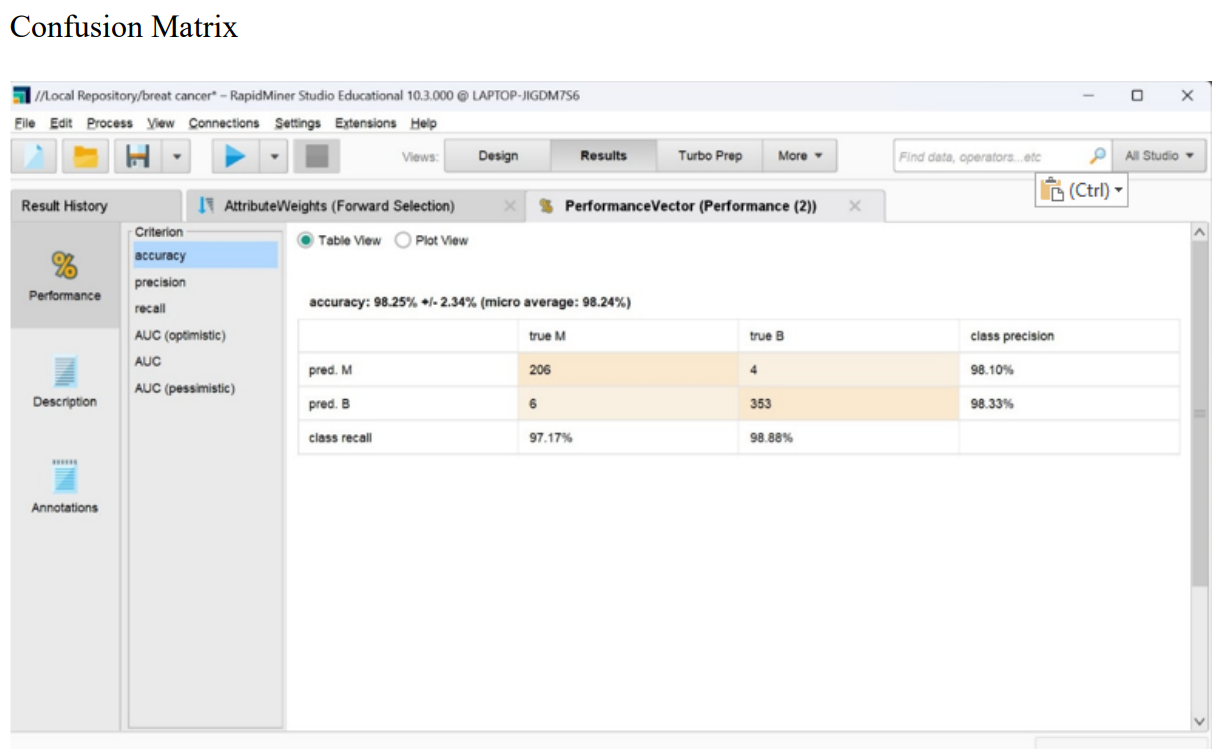
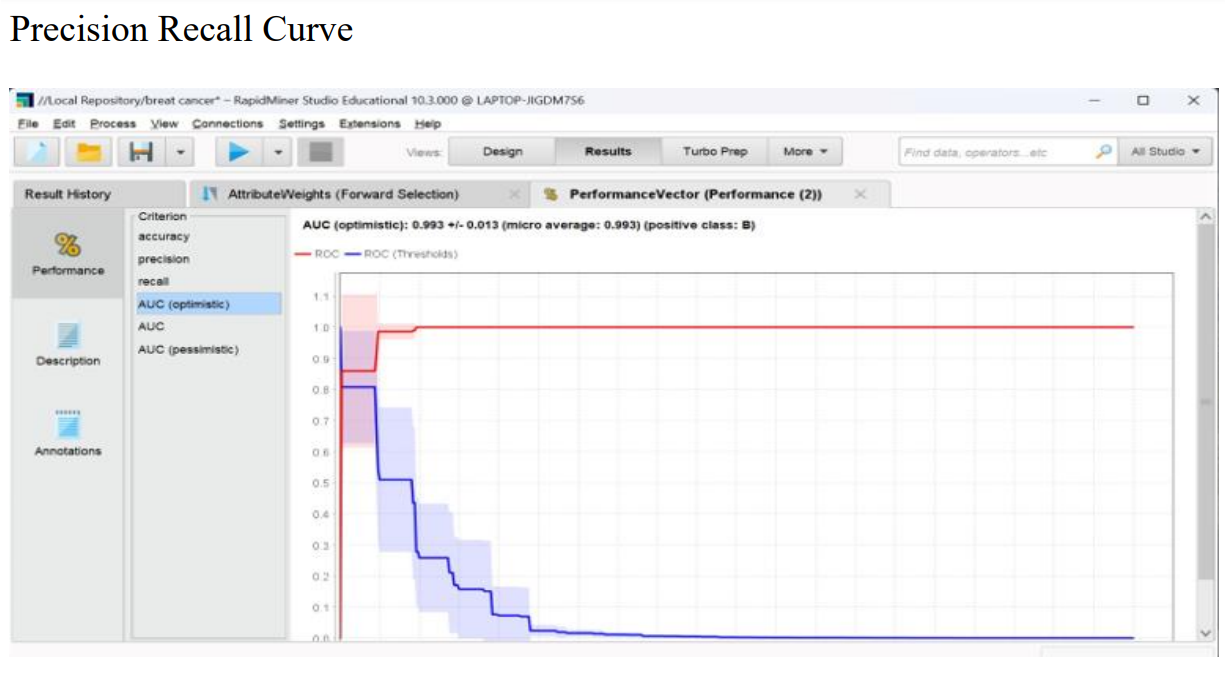
Results
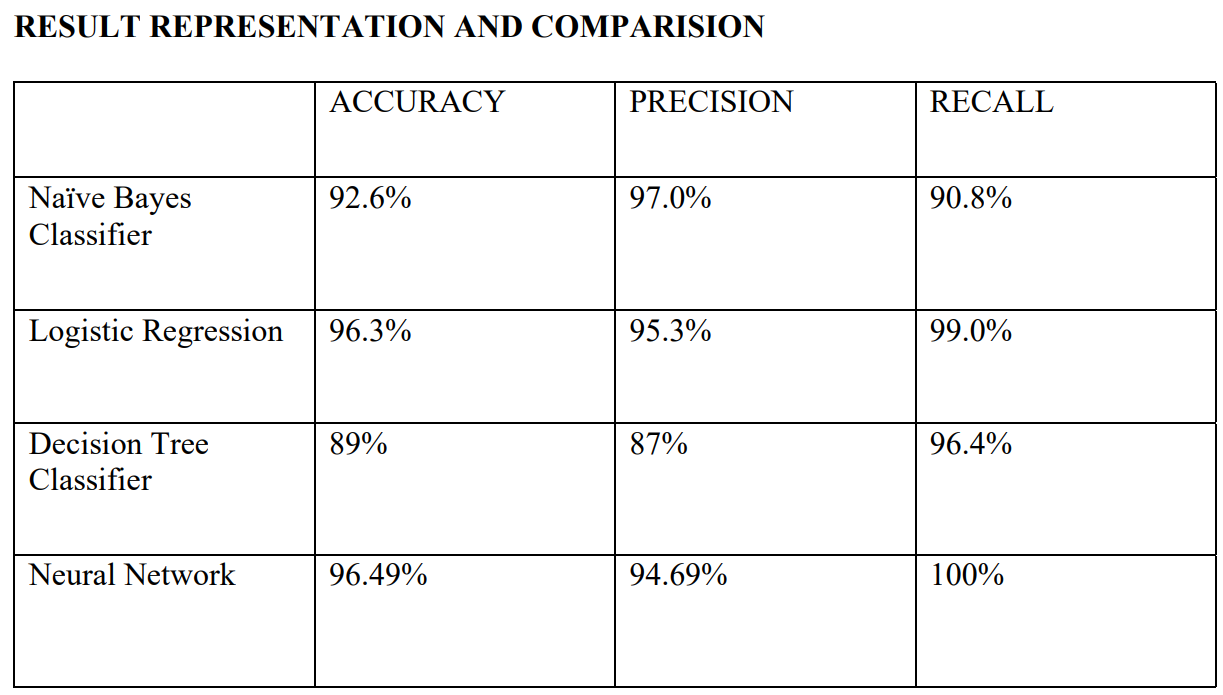
Conclusion
Now a days, one of the deadly diseases affecting women is breast cancer. In our work, the Breast Cancer Dataset was utilized and several ML algorithms were applied to assimilate the efficacy and usefulness of these algorithms to find the highest accuracy of classifying malignant and benign breast cancer. The correlation between different features of the dataset has been analysed for feature selection. The results will assist to pick the best ML algorithm for the construction of an automatic breast cancer diagnostic system. From our study, we can conclude that Neural Network Classifiers give the maximum accuracy with an accuracy of 96.5%. We will try to strengthen our work in future by handling a comparatively large dataset and incorporating some more functions such as breast cancer phase detection and so on. We hope that this study will contribute in the clinical application of breast cancer treatment.